

Orchestrator Functions
Orchestrator Functions orchestrate the execution sequence of other Durable Function types using procedural code within a workflow. They can contain conditional logic and error handling code, they can call other functions synchronously and asynchronously, they can take the output of one function and pass it in as input in subsequent functions and they can even initiate sub-orchestrations. In general they contain the orchestration code of a workflow. With Orchestrator Functions we can implement complex patterns such as Function Chaining, Fan Out/Fan In, Async HTTP APIs, Monitor, Human Interaction and Aggregator. We will explore the theory behind the most important of these patterns later on in this post, and sample code will be provided in subsequent posts.
Orchestrator Code Constraints
Code in Orchestrator Functions must comply to certain constraints. Failure to honor these constraints will result in unpredictable behavior. Before we list what those constraints are, it is important to understand why this is the case.
Under the covers, Orchestrators utilize the Durable Task Framework, which enables long running persistence in workflows using async/await constructs. In order to maintain persistence and be able to safely replay the code and continue from the appropriate point in the workflow, the Durable Functions extension uses Azure Storage Queues to trigger the next Activity Function in the workflow. It also uses Storage Tables to save the state of the orchestrations in progress. The entire orchestration state is stored using Event Sourcing. With Event Sourcing, rather than storing only the current state, the whole execution history of actions that result in the current state is stored. This pattern enables the Safe Replay of the orchestration’s code. Safe replay means that code that was executed before within the context of a particular orchestration instance, will not be executed again. For more clarity consider the following diagram:

This diagram shows a typical workflow involving an Orchestrator and two Activity Functions. As you can see, the Orchestrator sleeps and wakes up several times during the workflow. Every time it wakes up, it replays (re-executes) the entire code from the start to rebuild the local state. While the Orchestrator is doing that, the Durable Task Framework, examines the execution history stored in the Azure Storage Tables and if the code encounters an Activity Function that has already been executed, it replays that function’s result and the Orchestrator continues to run until the code is finished or until a new a new activity needs to be triggered.
To ensure reliable execution of the orchestration state, Orchestrator Functions must contain deterministic code; meaning it must produce the same result every time it runs. This imposes certain code constraints such as:
- Do not generate random numbers or GUIDs
- Do not ask for current dates and times. If you have to, then use IDurableOrchestrationContext.CurrentUtcDateTime
- Do not access data stores such as databases
- Do not look for configuration settings
- Do not write blocking code such as I/O code or Thread related code
- Do not perform any async operations such as Task.Run, HttpClient.SendAsync etc
- Do not use any bindings including orchestration client and entity client
- Avoid using static variables
- Do not use environment variables
This is not a comprehensive list but you can already get the idea that code in Orchestration Functions should be limited only to workflow orchestrations code. All these things you cannot do in Orchestrators you can and should be doing in Activity or Entity Functions that are invoked by the Orchestrators. For a full list and a lot more details about these constraints you can go to the Microsoft Learn site here.
Workflow Patterns
Now that we have learned the basic building blocks of Durable Functions we can begin exploring the different patterns that become available for us to implement. As a reminder, in this post we will only be covering the theory behind some of these patterns. Actual sample implementations will follow in subsequent posts.
Pattern 1: Function Chaining
The first pattern we can implement using Durable Functions is the Function Chaining pattern. Imagine any scenario of a workflow that requires multiple sequential steps to happen to accomplish a goal. Each step depends on the previous step to be completed before it can be executed, and steps may or may not require as input the output of a previous step.
In the following diagram we can see a Function Chaining pattern of a fictitious automatic espresso coffee maker machine. The pattern utilizes a Client Function (starter) that triggers an Orchestrator Function and the Orchestrator executes 4 Activity Functions in sequence.
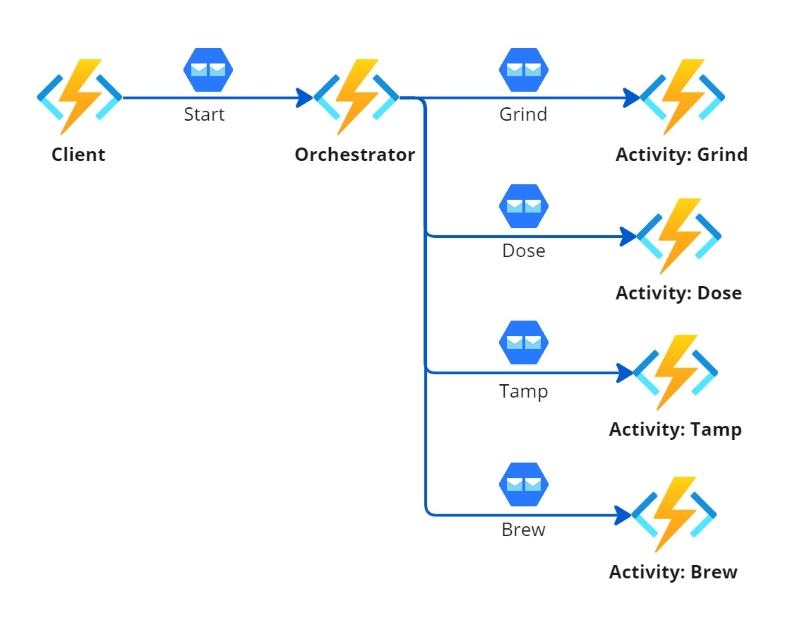
The power that comes with Durable Functions and specifically the orchestration, is that we can now introduce complex logic and error handling to gracefully handle errors in any step of the workflow or execute different tasks based on certain activity outputs. This would be much harder to do if we used regular functions that called one another. In addition to that we also have the benefits of the Durable Task Framework, that allows the workflow to go to sleep while an activity executes and then wake up and execute the appropriate next step.
Pattern 2: Fan out/fan in
Another powerful pattern we can implement is the Fan out/fan in pattern. This pattern fits well in scenarios when we want to execute multiple similar tasks in parallel, and then wait for them all to complete before we execute the next task. For example let’s consider now that the automated coffee maker machine can prepare multiple coffees. As the owner of the coffee shop, when I get an order from a group of 3 people, I want to prepare the 3 coffees at the same time and serve them together. In Function terms, what we can do is wrap the coffee workflow in one orchestration and then kick off 3 instances of that orchestration from a parent orchestrator, making it in a sense a sub-orchestration. This is depicted in the following diagram.

Pattern 3: Human Interaction
So far we have seen patterns that provide fully automated solutions. But how about workflows that require human intervention? Well there is a way to solve those types of scenarios as well. The Durable Functions Orchestrator context exposes a method called WaitForExternalEvent(). This method also accepts a TimeSpan parameter so that we can set a timer specifying how long we would wait for an external event to happen before continuing the workflow. This is pretty powerful, and I should point out here that no extra charges incur if the function is running in a consumption plan while waiting.
So lets assume that we are building a workflow that handles an on-boarding process for a new employee. As we can see in the diagram below, the Orchestrator first gets the offer letter from storage and then sends an email to the candidate. At this point the Orchestrator goes to sleep and waits for human interaction, which in this case happens when the candidate clicks on the acceptance link inside the email. This link invokes a regular HTTP Trigger Function and this new function in turn invokes the Orchestrator by raising the RaiseEventAsync() event which is part of the IDurableOrchestrationClient interface.

Wrapping Up
As we have seen, Azure Durable Functions provide a lot of useful functionality that allows us to create powerful workflows. Serverless Computing is a revolutionary platform that we can use to building software on. It allows us to focus on coding and completely forget about the nuances of infrastructure and operating systems. We can create services that scale in and out automatically to meet demand, handle complex workflows, pay only for the compute power we use (in a consumption plan) and save time and effort because we do not have to maintain any of the infrastructure.
We have focused on the fundamental theory of the most important aspects of Durable Functions in this first post of the series. In subsequent posts we will dive deeper into the setup, development and deployment of Durable Functions. Stay tuned!